Using regex to strip specific html tags using JavaScript
A few weeks back I had to tackle a problem. I’ve been working on a set of JavaScript based eBook readers with not a few constraints involved because of the target market. One of the features I needed to implement was the ability to highlight text using various colors. Sure, this wasn’t a big deal but I had a nightmare because the output wasn’t coming out as expected.
Here’s what I was getting:

as opposed to this:

And where was the problem? In the HTML that contained the contents of the page. We have a process in-house that does some nifty stuff and converts our PDF files to HTML, thus, helping us retain paging, number of words per line and lines per page.
What this process does is not so important as its output. Here’s the html that generated the “skippy” highlights:
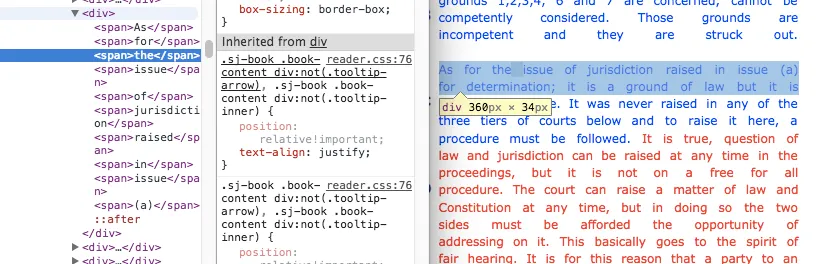
Notice how each word on the highlighted line is wrapped by a “span” tag? That’s the issue! The highlight code, in trying not to interfere with the page’s markup just picks words inside tags and wraps them with a tag and adds a custom highlight css class.
Here’s the markup that would generate the “smooth” highlight:
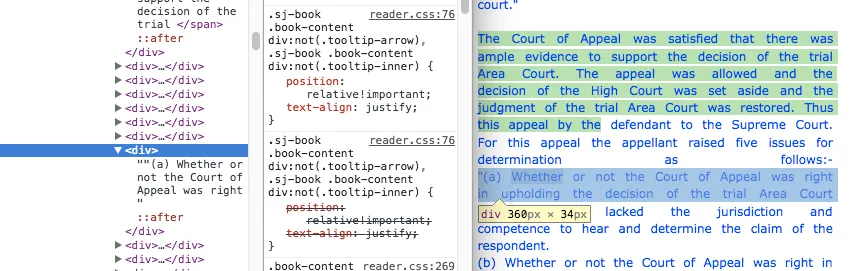
See the difference?
So, after months of ignoring the problem and reporting to management that it’s a small issue, I finally came around to fixing it and solved it with quite a few lines of CoffeeScript code:
theContent = pageObject.content.replace(/<span[^>]+\?>/i, '')
.replace /<\/span>/i, ''
.replace /<[//]{0,1}(SPAN|span)[^><]*>/g, ""
Here’s the JavaScript equivalent:
var theContent = pageObject.content.replace(/<span[^>]+\?>/i, '').replace(/<\/span>/i, '').replace(/<[//]{0,1}(SPAN|span)[^><]*>/g, "");
And voila! My headache was solved! Looks easy but I had to scour StackOverflow for this and I just thought I’d save myself the headache of looking for this all over again at a later time.